Countries Segmentation
Data Source: Here
Data Exploration
This projects aims to classify countries based on its parameters using clustering algorithm. There are several variables in the data, however only two variables are used for the project which are:
- Income: Net income per person
- Life Expectancy: The average number of years a new born child would live
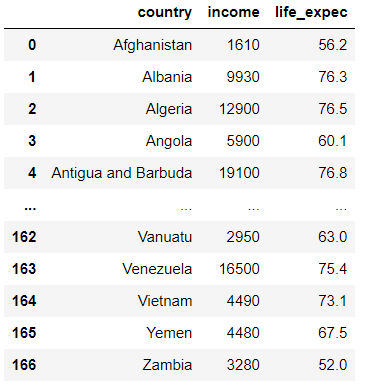
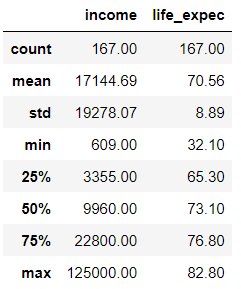
It is essential to discover the statistical summary of the variables as shown below
Model Training
The model used is K-Means Clustering, therefore it is vital to determine the K value (number of groups) by training the models using 1 K to 10 K in which for each K the Within-Cluster Sum of Square (WCSS) value is calculated then the result is plotted.
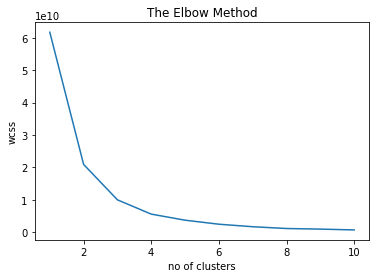
By using the plotted result of different K value, the best K value is when the next line is flat in other words, when the difference in WCSS is not significant to the next K Value.
The K value of 3 is selected based on the Elbow Method.
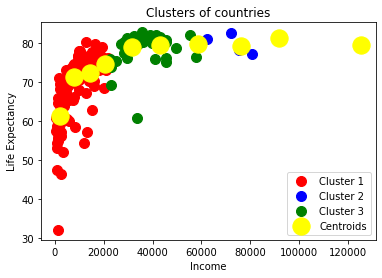
Clustering Description
- Cluster 1: Countries with low to high Expectancy and low income
- Cluster 2: Countries with high Expectancy and high income
- Cluster 3: Countries with low Expectancy and medium income
Checkout the source code on Github